How to Keep Personalization Alive When Millions Show Up at Once
Implementing precomputation to safeguard personalization calls on a streaming service API during vertical traffic spikes.

On a high-traffic day in early October, ContentWise UX Engine served recommendations to 2.9 million distinct users on a major European streaming platform. 84.65% got fully personalized results. The remaining 15% didn’t. The system did not fail, but the spike outpaced the autoscaler and the fallback kicked in. That fallback is correct behavior. It’s also a problem worth solving before the World Cup.
Autoscaling has a physical constraint: it takes time. A sudden spike driven by a live sports event, a premiere, or breaking news can outpace a cloud autoscaler by minutes.
During those minutes, the safe fallback is to serve unpersonalized responses rather than degrade the overall service. Understanding exactly how often this happens, and under what conditions, is the first step toward fixing it.
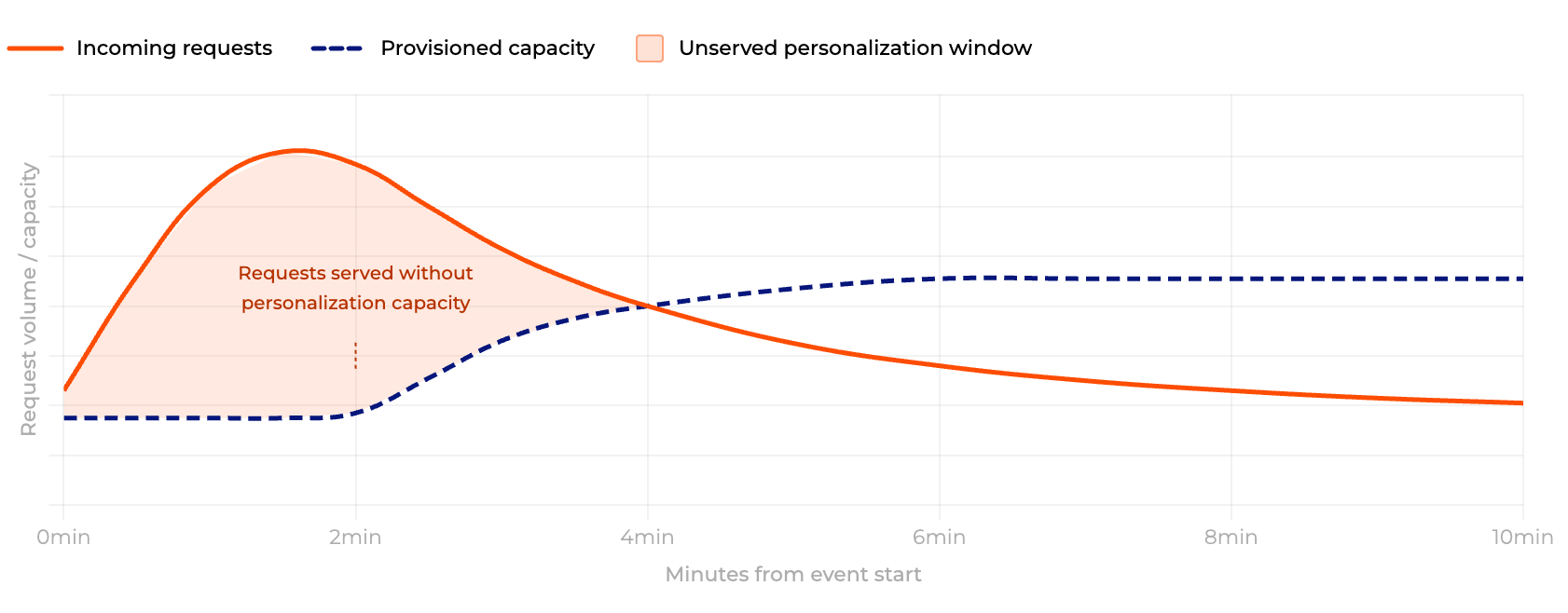
What does personalization fallback data look like during a live event?
ContentWise UX Engine serves personalization for a major European streaming platform. On an ordinary high-traffic day in early October, we processed recommendations for 2.9 million distinct users over 24 hours.
Of those, 84.65% received fully personalized recommendations throughout their session. About 15% received at least one unpersonalized response, and 3.49% received no personalization at all. Fewer than 5% of total calls were served as unpersonalized.
Those numbers look acceptable, but they are not good enough.
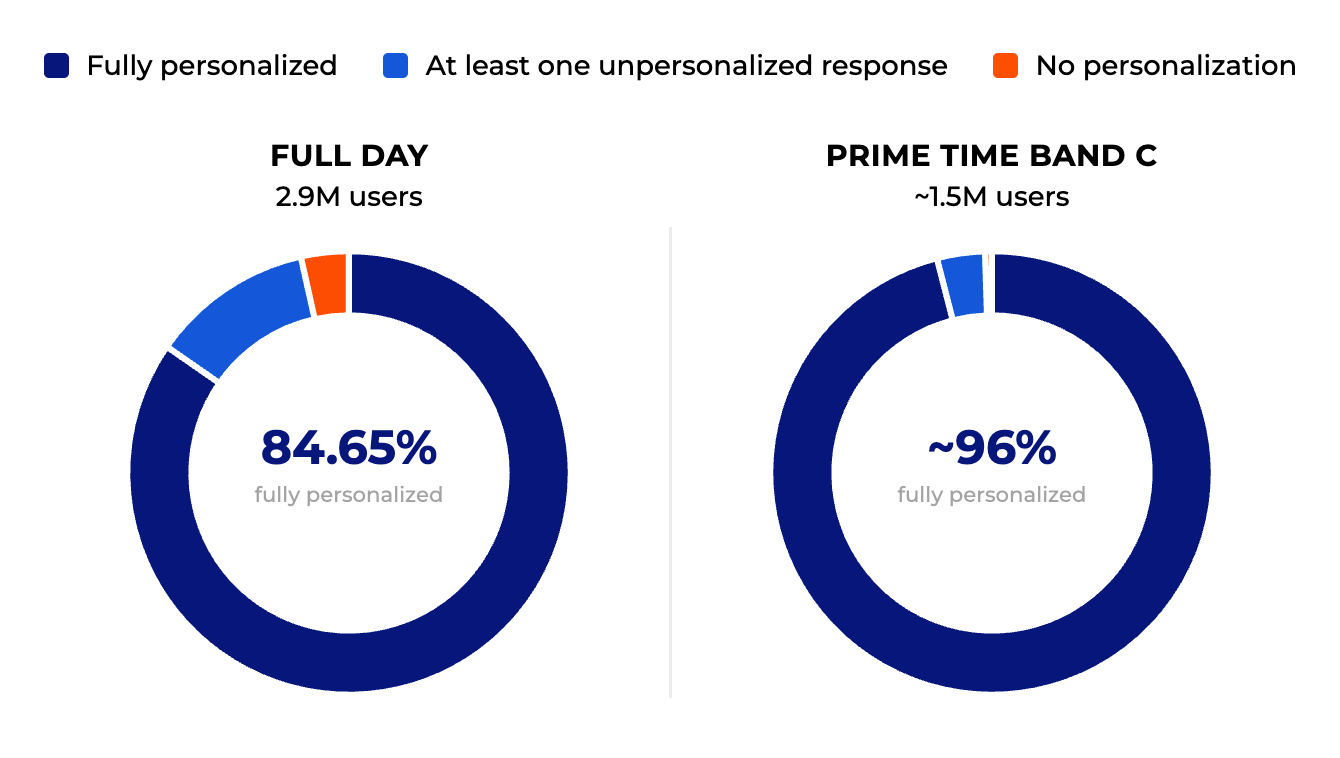
During prime time — a five-hour Band C window with roughly 1.5 million distinct active users — roughly 4% of users encountered an unpersonalized response, and about 2% of calls were served outside the personalization path.
The engineering reason is straightforward: vertical spikes don’t scale. A user surge driven by a single live event hits fast and steep. The autoscaler is optimized for gradual growth curves, not walls. The fallback guarantees availability and protects response times. What it can’t do is preserve the user experience you spent months tuning.
Why does autoscaling fail to protect personalization during live sports events?
Standard autoscaling is effective for predictable, ramp-shaped load. Add more pods, scale out the inference layer, pre-warm during anticipated peaks. This works when “anticipated” means hours or days of lead time.
Live sports typically breaks that model. The start of a World Cup match is an instantaneous event with millions of concurrent logins arriving within the same minutes, not the same hour. By the time the autoscaler detects the load and provisions capacity, a significant percentage of requests have already been served. Whatever was in the queue at that moment gets the unpersonalized fallback.
There is also a compounding problem that isn’t related to real users at all. Traffic analysis at the same platform showed a distinct overnight pattern: starting in mid-September, overnight calls increased sharply and stabilized at a new, higher baseline. By late in the period, roughly 20–30% of overnight calls were exceeding the Band A threshold. Behavioral analysis revealed the signature: approximately 500,000 user IDs making exactly six requests per session, every night, in the same time window, with zero correlation to playback events or onward journey clicks.
The system was being scraped. And the tell was in what those users didn’t access: “more like this” pages, search, playback… all showed natural behavior. Only the homepage UX references spiked. Cross-referencing GET reads against POST events confirmed no content was being delivered.
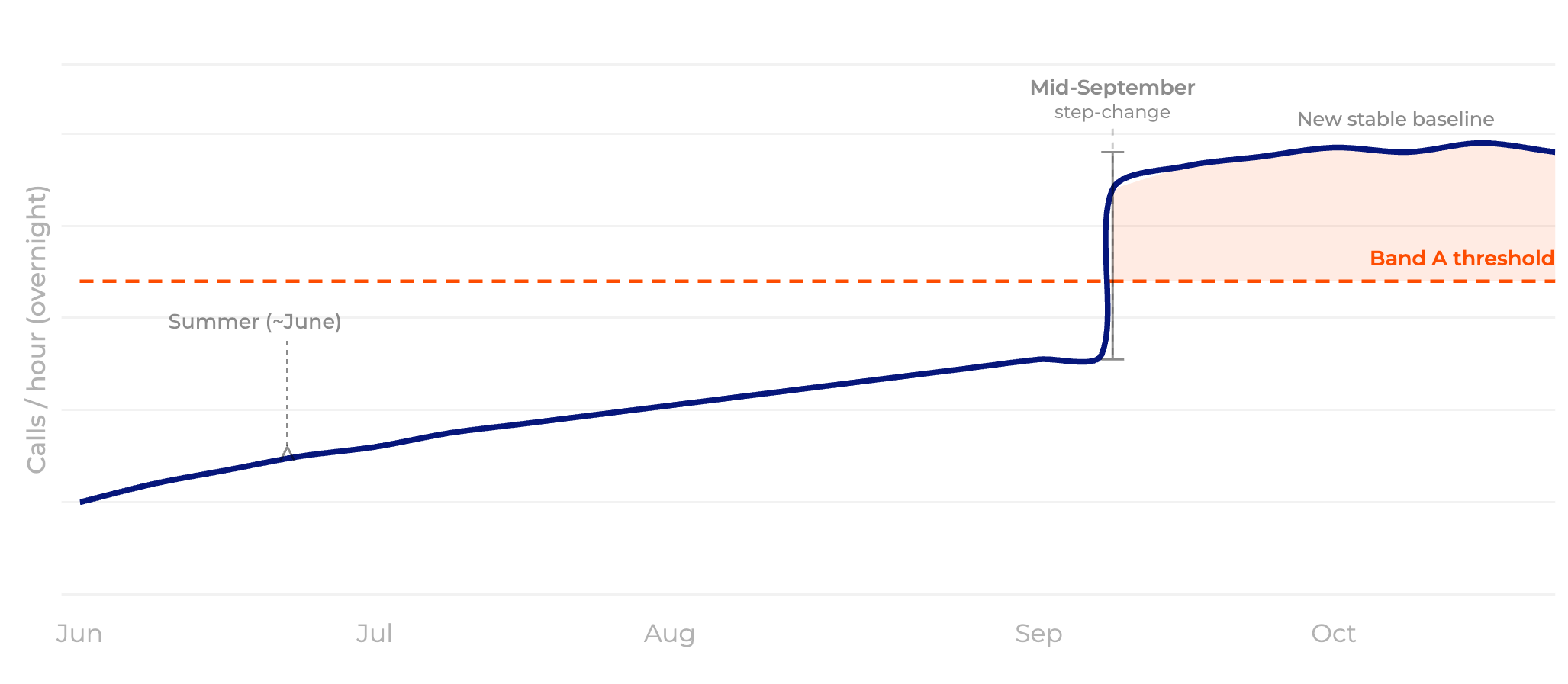
Scraping doesn’t just waste infrastructure. It consumes capacity that personalization needs, and it skews the baselines you use to plan for real event peaks.
If you suspect the same pattern on your platform: check for IP reuse across the anomalous user IDs, verify whether the traffic correlates to any internal security assessments or performance tests, and treat search endpoints as a separate category, as they are a common scraping entry point.
How does precomputation solve the live event personalization spike problem?
The right response to instantaneous spikes is not faster autoscaling. It is removing the dependency on real-time computation during the spike entirely.
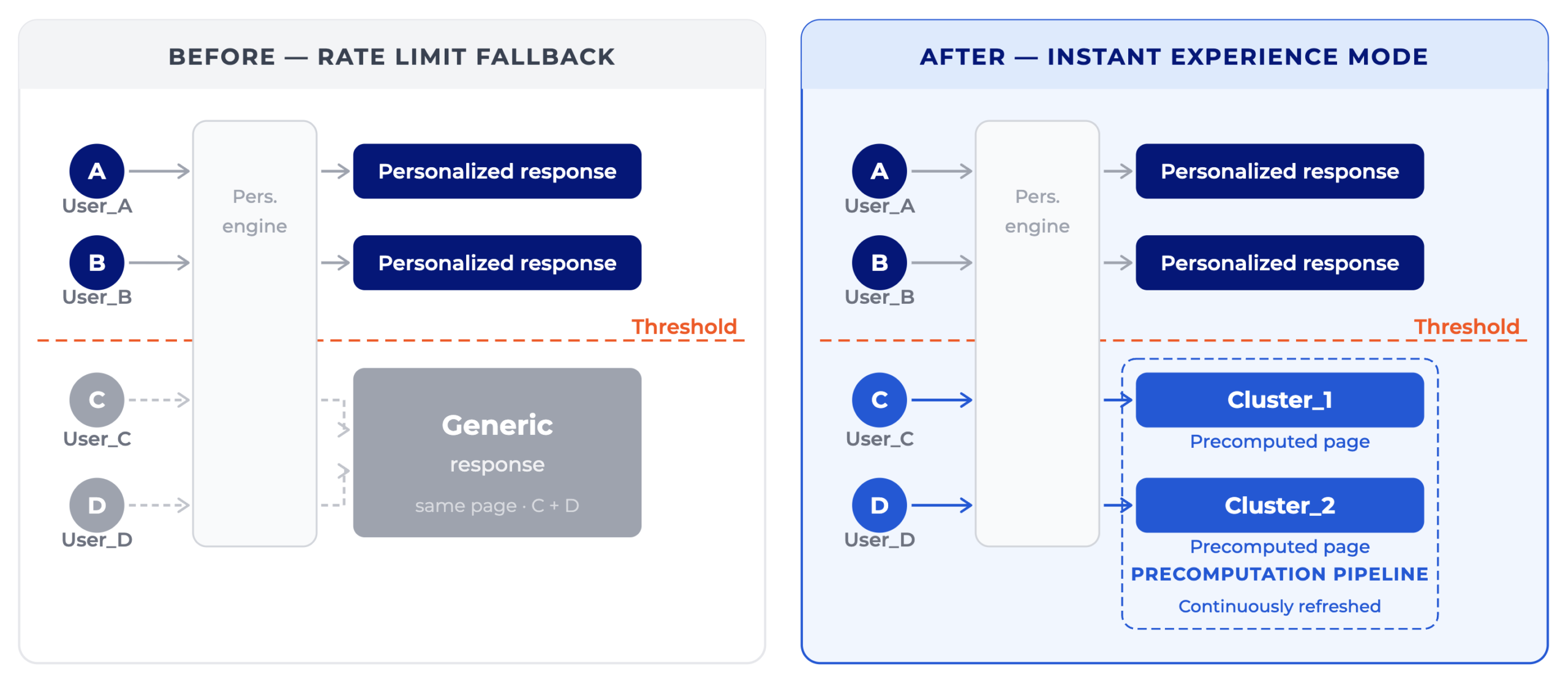
UX Engine 10 introduces a precomputation layer called Instant Experience Mode. Rather than compute personalization on demand when a request arrives, the system continuously builds and refreshes page structures, carousels, and item recommendations for up to 1,000 dynamic micro-clusters. When the spike hits, the engine serves pre-optimized pages without waiting for real-time inference.
The critical design decision is what defines a micro-cluster. A naive implementation collapses everyone into one bucket and serves the same page to every user during the peak. That reproduces the unpersonalized fallback in a different form. Instant Experience Mode works differently: micro-clusters are built around meaningful behavioral and contextual signals, including favorite teams, entry path (direct vs. social vs. ad), content affinity profile, and editorial context.
A user arriving from a social post about a World Cup quarter-final match, whose history shows a strong preference for a specific team, lands in a cluster whose pre-built page leads with that team’s content and surfaces editorially curated collateral.
The experience is not individual-level personalization, but it is sharply different from a generic homepage. And it is served instantly, without infrastructure provisioning under fire.
The cluster assignments and pre-built pages are continuously refreshed between spikes. Serving from cache during the peak is not a degraded mode. It is the designed-for mode.
What do operators need to implement micro-cluster personalization?
Three things determine whether precomputed micro-clusters hold up under real World Cup conditions.
1. Define clusters around stable, discriminating signals
Effective micro-clusters are built around signals that are stable enough to precompute against in advance but discriminating enough to produce meaningfully different pages. For a sports event, team affinity and entry path (direct navigation vs. social referral vs. paid ad) are the right anchors — they are knowable before the spike and they predict content preference reliably.
Content recency preferences and viewing depth (casual viewer vs. engaged subscriber) add resolution. The goal is not maximum granularity: a thousand clusters, each with a well-reasoned definition, covers the meaningful variation in your audience during a peak event without the overhead of individual-level computation.
2. Treat refresh cadence as a background pipeline problem, not a serving problem
Pre-built cluster pages go stale. For a World Cup event, the content landscape changes hour by hour: matches end, highlights go live, editorial teams publish. The precomputation layer must refresh on a cadence that keeps cluster pages current, but that refresh must be fully decoupled from request-time computation.
This is an architectural separation that matters under load. The serving path reads from precomputed state; it never triggers recomputation. The refresh pipeline runs continuously in the background, writing new cluster state that the serving path picks up on the next read cycle. Treating these as the same system is the design mistake that reintroduces latency at spike time.
3. Track events on cluster-served sessions to protect post-event personalization
Users who arrive during a World Cup match may be first-time or infrequent visitors. Even though they were served a cluster page rather than an individually computed response, their interaction events during the peak are valuable signals. Those events need to be captured, attributed to the correct user profile, and folded into profile updates so that post-event recommendations reflect what users actually engaged with during the spike.
Treating cluster-served users as opaque, i.e. recording that a page was served but not what they did with it, discards re-engagement signal at the exact moment when new audiences are most likely to form a lasting relationship with the platform.
The API integration
Wiring micro-cluster resolution into existing UX Engine calls requires one additional parameter. Under normal operating conditions:
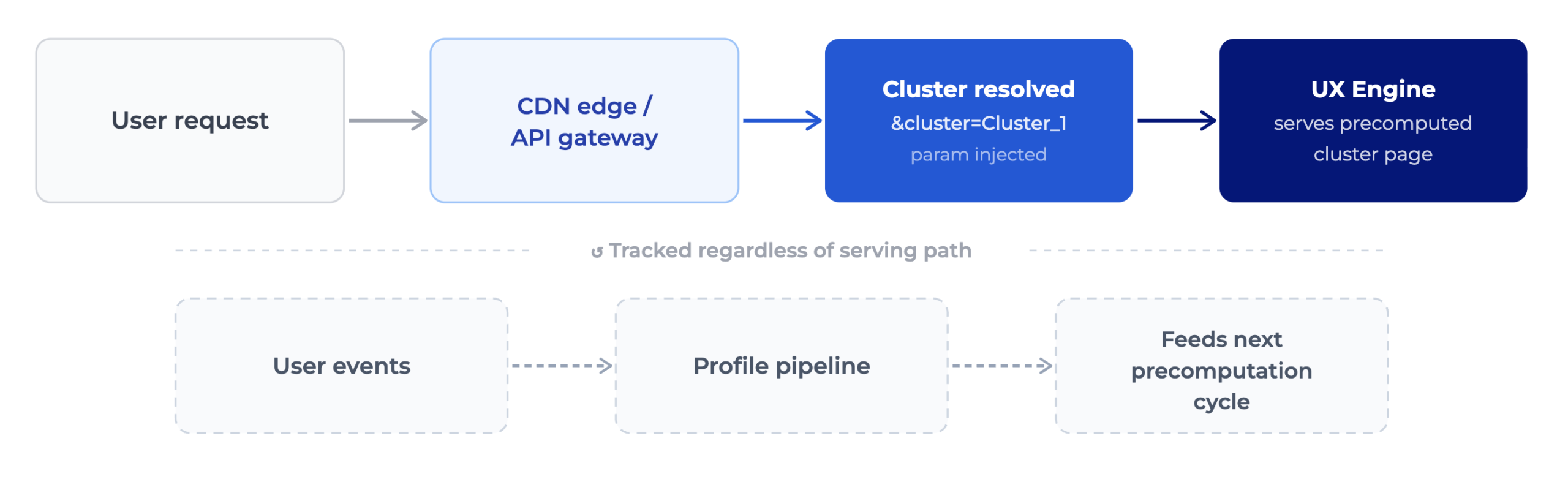
When the system routes a request to a precomputed cluster:
GET /recommendations?user=User_A&context=homepage&cluster=Cluster_1
The cluster assignment is resolved upstream, at the CDN edge, the API gateway, or a lightweight pre-classification service, and injected before the call reaches the recommendation engine.
The engine then serves the precomputed cluster response rather than triggering real-time inference. User events are still tracked regardless of serving path, preserving the profile data needed for post-event re-engagement.
What are the tradeoffs between autoscaling, generic fallback, and micro-cluster personalization?
| Approach | Spike handling | Personalization on quality at limit | Infrastructure cost | Operational complexity |
|---|---|---|---|---|
| Autoscaling only | Poor for vertical spikes | Full (until it fails) | Variable (can be extreme) | Low |
| Rate limit + generic fallback | Excellent | Drops to zero above threshold | Predictable | Low |
| Rate limit + micro-clusters | Excellent | Degrades gracefully to cluster level | Predictable + precompute overhead | Medium |
| Aggressive pre-provisioning | Excellent | Full | High (sustained) | Low |
Micro-clusters don’t replace autoscaling or pre-provisioning. They change what the fallback looks like, which changes the risk profile of under-provisioning. You can take a more conservative pre-provision posture knowing the overflow path still delivers relevant experiences, rather than needing to over-provision to keep the personalized fraction as high as possible.
What changes with this architecture is that the fallback is no longer a single unpersonalized response served to every user in the overflow queue. It is a set of up to a thousand responses, each built for a defined audience segment, continuously refreshed, and served without latency.
That is a materially different user experience. And it is one that operators can instrument, tune, and improve before the next spike arrives, rather than after.
What is Instant Experience Mode in ContentWise UX Engine?
Instant Experience Mode is a precomputation layer in ContentWise UX Engine 10 that continuously builds and refreshes personalized pages for up to 1,000 dynamic micro-clusters. During traffic spikes, the engine serves these pre-optimized pages without triggering real-time inference, eliminating the dependency on autoscaling during instantaneous load events.
Why does autoscaling fail to protect personalization during live sports events?
Autoscaling is optimized for gradual, ramp-shaped load growth. A live event spike — such as a World Cup match kick-off — creates millions of concurrent sessions in seconds, faster than cloud autoscalers can detect, provision, and warm new capacity. The result is a 2-4 minute window where requests are served without personalization capacity.
What is a micro-cluster in personalization?
A micro-cluster is a defined audience segment used to pre-build personalized pages before a traffic spike occurs. In ContentWise UX Engine, micro-clusters are defined around behavioral and contextual signals — such as team affinity, entry path, and content preferences — and can number up to 1,000 per deployment.
How does cluster assignment work at the API level?
Cluster assignment happens upstream of UX Engine at the CDN edge or API gateway. The resolved cluster is injected as a parameter before the call reaches the recommendation engine: GET /recommendations?user=User_A&context=homepage&cluster=Cluster_1. This means the engine itself is never burdened with classification logic during a spike.
What is the difference between generic fallback and micro-cluster personalization?
Generic fallback serves a single identical response to every user above the personalization threshold. Micro-cluster personalization resolves overflow requests to one of up to 1,000 precomputed audience segments, each with a distinct page built around behavioral signals. Users still receive differentiated experiences during the spike, rather than a one-size-fits-all page.